Overview
DANT is available in both MATLAB and Python versions for tracking neurons across days with high-density probes (Neuropixels).
Pipeline
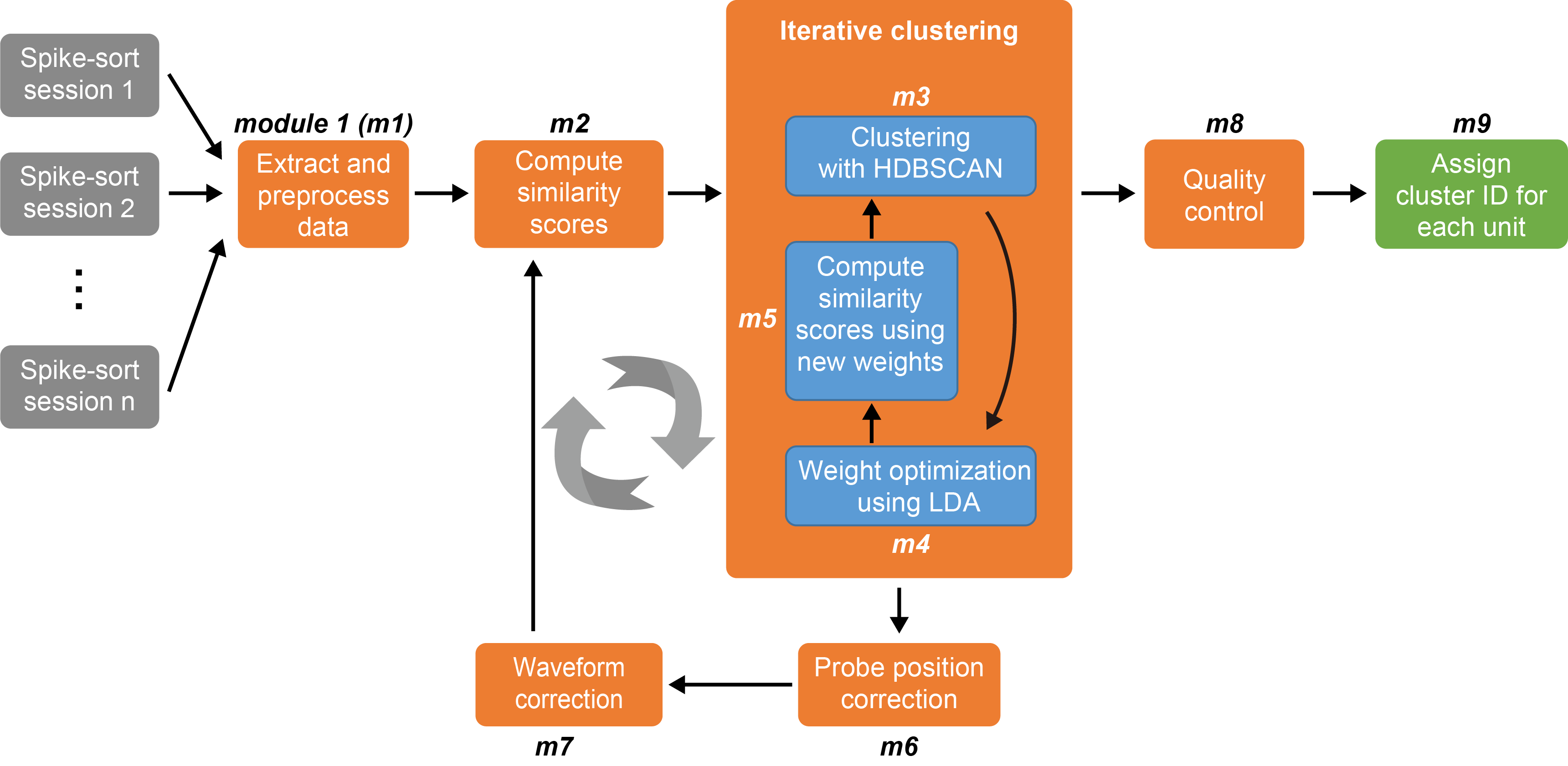
DANT takes well spike-sorted data as input and assigns a unique cluster ID to each unit as output. DANT does not require a user-defined “threshold” to filter good matches, providing a fully automatic way to track the same neurons across days to months.
Following spike sorting of each session \((1, 2, \ldots, n)\) independently, well-isolated units from each session are provided as input to DANT. Features for similarity analysis are extracted from each unit (Module 1, m1), including spike waveforms across all channels and, optionally, autocorrelograms (ACGs) as well as peri-event time histograms (PETHs) or peri-stimulus time histograms (PSTHs) that capture functional properties. Similarity scores between unit pairs are then computed using feature-specific weights (equal weights of \(1/3\) per feature by default, m2), which are transformed into pairwise distances representing dissimilarity. A density-based clustering algorithm applied to these distances identifies matched units hypothesized to originate from the same neuron (m3). Using these provisional clusters, linear discriminant analysis (LDA) optimizes the feature weights to maximize discrimination between matched and unmatched pairs (m4), yielding updated similarity scores and distances (m5). Clustering is iterated until the weights stabilize and the results converge. Using matched pairs’ spatial information, relative probe movement is inferred jointly across sessions (m6), and spike waveforms are remapped to probe recording sites, correcting for movement-induced changes in waveform distributions across channels (m7). The m2–m7 loop is repeated according to the configured motion-correction schedule and early-stopping rule. The final clustering output (m3) then undergoes a quality control step (m8) to remove within-cluster pairs that fail the LDA-derived similarity criterion. Clusters are then assigned IDs (m9) representing units recorded across multiple sessions, from 2 up to \(n\), that are hypothesized to originate from the same neuron.
The iterative core of the pipeline is formed by the clustering loop and the motion correction loop, corresponding to repeated execution of m2–m7. These loops alternately refine the estimated probe motion, feature weights, corrected waveforms, and clustering results. Click on the linked sections for details.